
OnYouTube, I watched a Mac user who had bought an iMac last year. It was maxed out with 40 GB of RAM costing him about $4,000. He watched in disbelief how his hyperexpensive iMac was being demolished by his new M1 Mac Mini, which he had paid a measly $700 for.
In real-world test after test, the M1 Macs are not merely inching past top-of-the-line Intel Macs, they are destroying them. In disbelief, people have started asking how on earth this is possible?
If you are one of those people, you have come to the right place. Here I plan to break it down into digestible pieces exactly what it is that Apple has done with the M1. Specifically the questions I think a lot of people have are:
- What are the technical reasons this M1 chip is so fast?
- Has Apple made some really exotic technical choices to make this possible?
- How easy will it be for the competition such as Intel and AMD to pull the same technical tricks?
Sure you could try to Google this, but if you try to learn what Apple has done beyond the superficial explanations, you will quickly get buried in highly technical jargon such as M1 using very wide instruction decoders, enormous reorder buffer (ROB), etc. Unless you are a CPU hardware geek, a lot of this will simply be gobbledygook.
To get the most out of this story I advise reading my earlier piece: “What Does RISC and CISC mean in 2020?” There I explain what a microprocessor (CPU) is as well as various important concepts such as:
- Instruction set architecture (ISA)
- Pipelining
- Load/store architecture
- Microcode vs. micro-operations
But if you are impatient, I will do a quick version of the material you need to understand to grasp my explanation of the M1 chip.
What is a microprocessor (CPU)?
Normally when speaking of chips from Intel and AMD we talk about central processing units (CPUs) or microprocessors. As you can read more about in my RISC vs. CISC story, these pull in instructions from memory. Then each instruction is typically carried out in sequence.
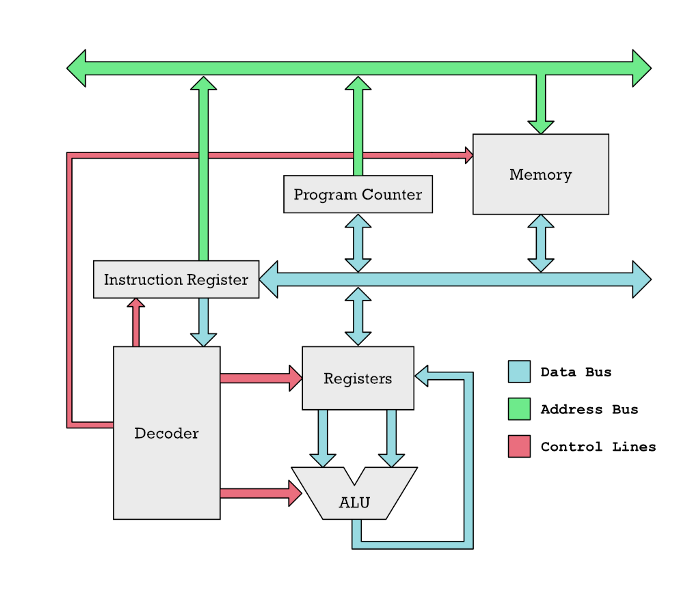
A CPU at its most basic level is a device with a number of named memory cells called registers and a number of computational units called arithmetic logic units (ALU). The ALUs perform things like addition, subtraction, and other basic math operations. However, these are only connected to the CPU registers. If you want to add up two numbers, you have to get those two numbers from memory and into two registers in the CPU.
Here are some examples of typical instructions that a RISC CPU as found on the M1 carries out.
load r1, 150
load r2, 200
add r1, r2
store r1, 310Here r1 and r2 are the registers I talked about. Modern RISC CPUs cannot do operations on numbers that are not in a register like this. For example, it cannot add two numbers residing in RAM in two different locations. Instead, it has to pull these two numbers into a separate register. That is what we do in this simple example. We pull in the number at memory location 150 in the RAM and put it into register r1 in the CPU. Next, we put the contents of address 200 into register r2. Only then can the numbers be added with the add r1, r2 instruction.


The concept of registers is old. For example, on this old mechanical calculator, the register is what holds the numbers you are adding. Likely the origin of the term cash register. The register is where you registered input numbers.
The M1 is not a CPU!
But here is a very important thing to understand about the M1:
The M1 is not a CPU, it is a whole system of multiple chips put into one large silicon package. The CPU is just one of these chips.
Basically, the M1 is one whole computer onto a chip. The M1 contains a CPU, graphical processing unit (GPU), memory, input and output controllers, and many more things making up a whole computer. This is what we call a system on a chip (SoC).


Today if you buy a chip — whether from Intel or AMD — you actually get what amounts to multiple microprocessors in one package. In the past computers would have multiple physically separate chips on the motherboard of the computer.


However because we are able to put so many transistors on a silicon die today, companies such as Intel and AMD began putting multiple microprocessors onto one chip. Today we refer to these chips as CPU cores. One core is basically a full independent chip that can read instructions from memory and perform calculations.
This has for a long time been the name of the game in terms of increasing performance: Just add more general-purpose CPU cores. But there is a disturbance in the force. There is one player in the CPU market which is deviating from this trend.
Apple’s not so secret heterogeneous computing strategy
Instead of adding ever more general-purpose CPU cores, Apple has followed another strategy: They have started adding ever more specialized chips doing a few specialized tasks. The benefit of this is that specialized chips tend to be able to perform their tasks significantly faster using much less electric current than a general-purpose CPU core.
This is not entirely new knowledge. For many years already specialized chips such as the graphical processing units (GPUs) have been sitting in Nvidia and AMD graphics cards performing operations related to graphics much faster than general-purpose CPUs.
What Apple has done is simply to take a more radical shift toward this direction. Rather than just having general-purpose cores and memory, the M1 contains a wide variety of specialized chips:
- Central processing unit (CPU) — the “brains” of the SoC. Runs most of the code of the operating system and your apps.
- Graphics processing unit (GPU) — handles graphics-related tasks, such as visualizing an app’s user interface and 2D/3D gaming.
- Image processing unit (ISP) — can be used to speed up common tasks done by image processing applications.
- Digital signal processor (DSP) — handles more mathematically intensive functions than a CPU. Includes decompressing music files.
- Neural processing unit (NPU) — used in high-end smartphones to accelerate machine learning (A.I.) tasks. These include voice recognition and camera processing.
- Video encoder/decoder — handles the power-efficient conversion of video files and formats.
- Secure Enclave — encryption, authentication, and security.
- Unified memory — allows the CPU, GPU, and other cores to quickly exchange information.
This is part of the reason why a lot of people working on images and video editing with the M1 Macs are seeing such speed improvements. A lot of the tasks they do can run directly on specialized hardware. That is what allows a cheap M1 Mac Mini to encode a large video file without breaking a sweat while an expensive iMac has all its fans going full blast and still cannot keep up.
Read more about heterogeneous computing: Apple M1 foreshadows Rise of RISC-V.

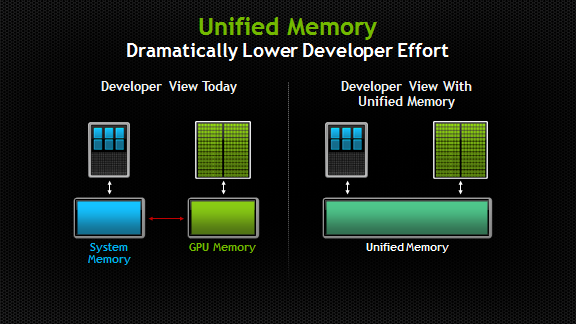
What is Special About Apple’s Unified Memory Architecture?
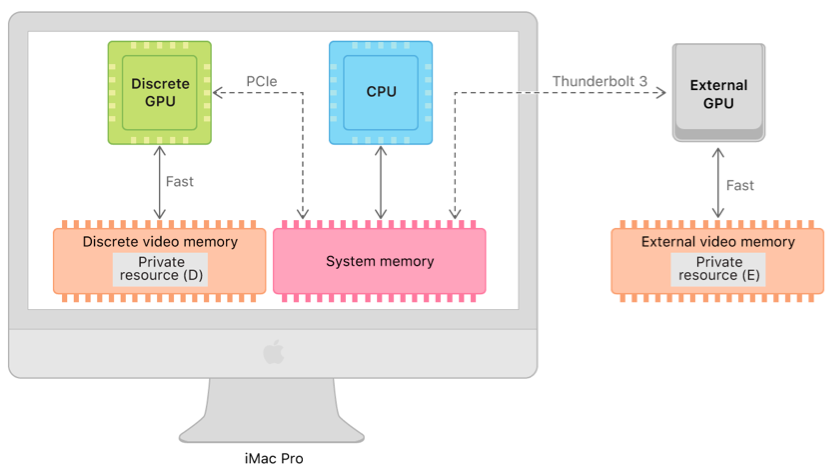
Apple’s “Unified Memory Architecture” (UMA) is a bit tricky to wrap your head around (I got it wrong first time I wrote it down here).
To explain why, we need to take a few steps back.
For a long time cheap computer systems have had the CPU and GPU integrated into the same chip (same silicon die). These have been famously slow. In the past saying “integrated graphics” was essentially the same as saying “slow graphics.”
These where slow for severals reasons:
Separate areas of this memory got reserved for the CPU and GPU. If the CPU had a chunk of data it wanted the GPU to use, it couldn’t say “here have some of my memory.” No, the CPU had to explicitly copy the whole chunk of data over the memory area controlled by the GPU.


CPUs and GPUs don’t want their memory served the same way. Let us do a silly food analogy: CPUs want their plate of data served very quickly by the waiter, but they are totally cool with small portion sizes. Imagine a fancy French restaurant with waiters on rollerblades to serve you really quickly.


GPUs in contrast are cool with the waiter being slow to serve the data. But the GPUs want enormous servings. They gobble massive amounts of data because they are massive parallel machines, that can chew through lots of data in parallel. Imagine an American junk food place, where the food takes some time to arrive because they are pushing a whole trolley of food to your seating area.
With such different needs, putting CPUs and GPUs on the same physical chip was not a great idea. The GPUs would sit there starving while given small French servings. The result was that there was no point in putting powerful GPUs on an SoC. The tiny portions of data served up, could easily be chewed up by a weak little GPU.
The second problem was that large GPUs produce a lot of heat and thus you cannot integrate them with the CPU without getting problems ridding yourself of the heat produced. Thus discrete graphics cards tend to look like the one below: Large beasts with massive cooling fans. They have special dedicated memory designed to serve the greedy cards massive amounts of data.


That is why these cards have high performance. But they have an achilles heel: Whenever they have to get data from the memory used by the CPU, this happens over a set of copper traces on the computer motherboard called a PCIe bus. Try chugging water through a super thin straw. It may get to your mouth fast, but the throughput is totally inadequate.
Apple’s Unified Memory Architecture tries to solve all these problems without having the disadvantages of old school shared memory. They achieve this in the following ways:
- There is no special area reserved just for the CPU or just the GPU. Memory is allocated to both processors. They can both use the same memory. No copying is needed.
- Apple uses memory which serves both large chunks of data and serves it fast. In computer speak that is called low latency and high throughput. Thus the need to be connected to separate types of memory is removed.
- Apple has gotten the watt usage of the GPU down, so that a relatively powerful GPU can be integrated without overheating the SoC. And ARM chips produce less heat, allowing the GPU to have a higher heat budget than a GPU on the same silicon die as an AMD or Intel CPU.
Some will say unified memory is not entirely new. It is true that different systems have had it in the past. But then the difference in memory requirements may not have been as large. Secondly what Nvidia calls Unified Memory is not really the same thing. In the Nvidea world Unified Memory simply means that there is software and hardware which takes care of automatically copying data back and forth between the separate CPU and GPU memory. Thus from a programmers perspective Apple and Nvidia Unified Memory may look the same, but it is not the same in a physical sense.
There is of course a tradeoff in this strategy. Getting this high bandwidth memory (big servings) require full integration which means you take away the opportunity from customers to upgrade their memory. But Apple seeks to minimize this problem by making the communication with the SSD disks so fast, that they essentially work like old fashion memory.
If SoCs Are So Smart, Why Don’t Intel and AMD Copy This Strategy?
If what Apple is doing is so smart, why is not everybody doing it? To some extent they are. Other ARM chip makers are increasingly putting in specialized hardware.
AMD has also started putting stronger GPUs on some of their chips and moving gradually toward some form of SoC with the accelerated processing units (APU) which are basically CPU cores and GPU cores placed on the same silicon die.


Yet there are important reasons why they cannot do this. An SoC is essentially a whole computer on a chip. That makes it a more natural fit for an actual computer-maker, such as HP and Dell. Let me clarify with a silly car analogy: If your business model is to build and sell car engines, it would be an unusual leap to begin manufacturing and selling whole cars.
For ARM, in contrast, this isn’t an issue. Computer makers such as Dell or HP could simply license ARM intellectual property and buy IP for other chips, to add whatever specialized hardware they think their SoC should have. Next, they ship the finished design over to a semiconductor foundry such as GlobalFoundries or TSMC, which manufactures chips for AMD and Apple today.


Here we get a big problem with the Intel and AMD business model. Their business models are based on selling general-purpose CPUs, which people just slot onto a large PC motherboard. Thus computer-makers can simply buy motherboards, memory, CPUs, and graphics cards from different vendors and integrate them into one solution.
But we are quickly moving away from that world. In the new SoC world, you don’t assemble physical components from different vendors. Instead, you assemble IP (intellectual property) from different vendors. You buy the design for graphics cards, CPUs, modems, IO controllers, and other things from different vendors and use that to design an SoC in-house. Then you get a foundry to manufacture this.
Now you got a big problem, because neither Intel, AMD, or Nvidia are going to license their intellectual property to Dell or HP for them to make an SoC for their machines.
Sure Intel and AMD may simply begin to sell whole finished SoCs. But what are these to contain? PC-makers may have different ideas of what they should contain. You potentially get a conflict between Intel, AMD, Microsoft, and PC-makers about what sort of specialized chips should be included because these will need software support.
For Apple this is simple. They control the whole widget. They give you, for example, the Core ML library for developers to write machine learning stuff. Whether Core ML runs on Apple’s CPU or the Neural Engine is an implementation detail developers don’t have to care about.
The fundamental challenge of making any CPU run fast
So heterogeneous computing is part of the reason but not the sole reason. The fast general-purpose CPU cores on the M1, called Firestorm, are genuinely fast. This is a major deviation from ARM CPU cores in the past which tended to be very weak compared to AMD and Intel cores.
Firestorm, in contrast, beats most Intel cores and almost beats the fastest AMD Ryzen cores. Conventional wisdom said that was not going to happen.
Before talking about what makes Firestorm fast it helps to understand what the core idea of making a fast CPU is really about.
In principle you accomplish in a combination of two strategies:
- Perform more instructions in a sequence faster.
- Perform lots of instructions in parallel.
Back in the ’80s, it was easy. Just increase the clock frequency and the instructions would finish faster. Every clock cycle is when the computer does something. But this something can be quite little. Thus an instruction may require multiple clock cycles to finish because it is made up of several smaller tasks.
However, today increasing the clock frequency is next to impossible. That is the whole “End of Moore’s Law” that people have been harping on for over a decade now.
Thus it is really about executing as many instructions as possible in parallel.
Multi-core or Out-of-Order processors?
There are two approaches to this.
- Add more CPU cores. Each core works independent and in parallel.
- Make each CPU core execute multiple instructions in parallel.
For a software developer, adding cores is like adding threads. Every CPU core is like a hardware thread.
If you don’t know what a thread is, then you can think of it as the process of carrying out a task. With two cores, a CPU can carry out two separate tasks concurrently: two threads. The tasks could be described as two separate programs stores in memory or it could actually be the same program performed twice. Each thread needs some bookkeeping, such as where in a sequence of program instructions the thread is currently at. Each thread may store temporary results which should be kept separate.
In principle, a processor can have just one core and run multiple threads. In this case, it simply halts one thread and stores current progress before switching to another. Later it switches back. This doesn’t bring much of a performance enhancement unless the thread has to frequently halt to:
- Wait for input from the user
- Data from a slow network connection, etc.
Let us call these software threads. Hardware threads mean you have actual physical CPU cores at your disposal to speed up things.

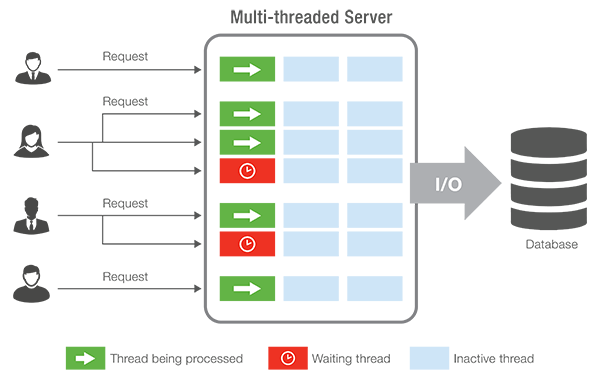
The problem with threads is that software developers have to write so called multi-threaded code. That is often difficult. In the past, this was some of the hardest code to write. However making server software multi-threaded tends to be easy. It is simply a matter of handling each user request on a separate thread. Thus in this case having lots of cores, is an obvious advantage. Especially for cloud services.


That is the reason why you see ARM CPU-makers such as Ampere making CPUs such as the Altra Max which has a crazy 128 cores. This chip is specifically made for the cloud. You don’t need crazy single-core performance, because in the cloud it is all about having as many threads as possible per watt to handle as many concurrent users as possible.
Read more about ARM CPUs with many cores: Are Servers Next for Apple?
Apple, in contrast, is on the complete opposite end of the spectrum. They make single-user devices. Lots of threads is not an advantage. Their devices are used for gaming, video editing, development, etc. They want desktops with beautiful responsive graphics and animations.
Desktop software is generally not made to utilize lots of cores. For example, computer games will likely benefit from eight cores, but something like 128 cores would be a total waste. Instead, you would want fewer but more powerful cores.
How Out-of-Order Execution Works
To make a more powerful core we need it to execute more instructions in parallel. Out-of-Order execution (OoOE) is a way to execute more instructions in parallel but without exposing that capability as multiple threads.
For an alternative solution read: Very Long Instruction Word Microprocessors
Developers don’t have to code their software specifically to take advantage of OoOE. Seen from the developer’s perspective it just looks like each core runs faster. Please note it is not a direct alternative to hardware threads. You want to use both, depending on the particular problem you are solving.
To understand how OoOE works, you need to understand some things about memory. Asking for data in one particular memory location is slow. But the CPU is capable of getting getting many bytes at the same time. Hence getting 1 specific byte in memory, takes no less time than getting 100 more bytes following that byte in memory.


Here is an analogy: Consider pickers in a warehouse. Could be the little red robots in the picture above. Moving to multiple locations spread all over takes time. But picking up items from slots adjacent to each other is quick. Computer memory is very similar. You can quickly fetch content of memory cells which are adjecent.
Data is sent across what we call a databus. You can think of it as a road or pipe between memory and different parts of the CPU where data gets pushed through. In reality, it is of course just some copper tracks conducting electricity. If the databus is wide enough you can get multiple bytes at the same time.
Thus CPUs get a whole chunk of instructions at a time to execute. But they are written to be executed one after the other. Modern microprocessors do what we call Out-of-Order execution (OoOE).
That means they are able to analyze a buffer of instructions quickly and see which ones depend on which. Look at the simple example below:
01: mul r1, r2, r3 // r1 ← r2 × r3
02: add r4, r1, 5 // r4 ← r1 + 5
03: add r6, r2, 1 // r6 ← r2 + 1Multiplication tends to be a slow process. So say it takes multiple clock cycles to perform. The second instruction will simply have to wait because its calculation depends on knowing the result that gets put into the r1 register.
However, the third instruction at line 03 doesn’t depend on calculations from previous instructions. Hence an Out-of-Order processor can begin calculating this instruction in parallel.
However more realistically we are talking about hundreds of instructions. The CPU is able to figure out all the dependencies between these instructions.
It analyses the instructions by looking at the inputs to each instruction. Do the inputs depend on output from one or more other instructions? By input and output, we mean registers containing results from previous calculations.
For example, the add r4, r1, 5 instruction depends on input from r1 which is produced by mul r1, r2, r3 . We can chain together these relationships into long elaborate graphs that the CPU can work through. The nodes are the instructions and the edges are the registers connecting them.
The CPU can analyze such a graph of nodes and determine which instructions it can perform in parallel and where it needs to wait for the results from multiple dependent calculations before carrying on.
Many instructions will finish early but we cannot make their results official. We cannot commit them; otherwise, we supply the result in the wrong order. To the rest of the world, it has to look as if the instructions were carried out in the same sequence as they were issued.
Like a stack, the CPU will keep popping done instructions from the top, until hitting an instruction that is not done.
Basically you got two forms of parallelism: One that the developer must deal with explicitly when writing code and one that is entirely transparent. Of course the latter relies on lots of transistors on the CPU dedicated to Out-of-Order Execution magic. This is not a viable solution for small CPUs with few transistors.
It is the superior Out-of-Order execution that is making the Firestorm cores on the M1 kick ass and take names. It is in fact much stronger than anything from Intel or AMD and they may never be able to catch up. To understand why, we need to get into some more technical details.
ISA Instructions vs Micro-Operations
Previously I skipped some details on how Out-of-Order Execution (OoOE) works.
Programs loaded into memory are made up of machine code instructions designed for specific Instruction-Set Architectures (ISA) such as x86, ARM, PowerPC, 68K, MIPS, AVR etc.
For instance the x86 instruction to fetch a number from memory location 24 into a register you may write:
MOV ax, 24x86 have registers named ax, bx, cx and dx(remember these are the memory cells inside the CPU you perform operations on). However the equivalent ARM instruction would look like this:
LDR r0, 24AMD and Intel processors understand the x86 ISA, while Apple Silicon chips, such as M1, understand the ARM Instruction-Set Architecture (ISA).
However internally the CPU works on an entirely different instruction-set invisible to the programmer. We call these micro-operations (micro-ops or μops). These are the instructions the Out-of-Order hardware works with.
But why can’t the OoOE hardware work with regular machine code instructions? Because the CPU needs to attach lots of different information to the instructions to be able to run them in parallel.
Thus while a normal ARM instruction may be 32-bit (32 digits of 0 and 1), a micro-op can be much longer. It contains information about its order.
01: mul r1, r2, r3 // r1 ← r2 × r3
02: add r4, r1, 5 // r4 ← r1 + 5
03: add r6, r2, 1 // r1 ← r2 + 1Consider if we run instruction 01: mul and 03: add in parallel. Both store their result in register r1 . If we write the result of instruction 03: add before 01: mul, then instruction 02: add will get the wrong input. Hence it is very important to keep track of instruction order. The order is stored with each micro-op. It also stores e.g. that instruction 02: add depends on output from 01: mul.
That is why we cannot have programs written using micro-ops. They contain lots of details specific to the internals of each microprocessor. Two ARM processors could have very different micro-ops internally.
Read more about CPUs with micro-ops like instructions: Very Long Instruction Word Microprocessors.
Also, micro-ops are usually easier to work with for the CPU. Why? Because they each do one simple limited task. Regular ISA instructions can be more complex causing a bunch of stuff to happen and thus frequently translate to multiple micro-ops. Thus the name “micro” comes from the small task they do, not the length of the instruction in memory.
For CISC CPUs there is usually no alternative but to use micro-ops otherwise the large complex CISC instructions would make pipelines and OoOE next to impossible to achieve.
RISC CPUs have a choice. So, for example, smaller ARM CPUs don’t use micro-ops at all. But that also means they cannot do things such as OoOE.
Why is AMD and Intel Out-of-Order execution inferior to M1?
But you wonder, why does any of this matter? Why is this detail important to know to understand why Apple has the upper hand on AMD and Intel?
It is because the ability to run fast depends on how quickly you can fill up a buffer of micro-operations. If you got a large buffer then the OoOE hardware will have an easier time to locate two or more instructions which it can run in parallel. But there is no point in having a large instruction buffer if you cannot refill it fast enough after instructions get picked and executed.
The ability to refill the instruction buffer quickly relies on the ability to quickly chop machine code instruction into micro-ops. The hardware units that does this are called decoders.
And finally we get to the killer feature of the M1. The biggest and meanest Intel and AMD microprocessor have a total of four decoders busy cutting machine code instructions into micro-ops.
But this is no match for the M1, which has an absolutely unheard of number of decoders: Eight. Significantly more than anybody else in the industry. That means it can fill up the instruction buffer much quicker.
To deal with this the M1 also has an instruction buffer which is 3x times larger than what is normal in the industry.
Why can’t Intel and AMD add more instruction decoders?
This is where we finally see the revenge of RISC, and where the fact that the M1 Firestorm core has an ARM RISC architecture begins to matter.
You see, an x86 instruction can be anywhere from 1–15 bytes long. RISC instructions have fixed length. Every ARM instruction is 4 bytes long. Why is that relevant in this case?
Because splitting up a stream of bytes into instructions to feed into eight different decoders in parallel becomes trivial if every instruction has the same length.
However, on an x86 CPU, the decoders have no clue where the next instruction starts. It has to actually analyze each instruction in order to see how long it is.
The brute force way Intel and AMD deal with this is by simply attempting to decode instructions at every possible starting point. That means x86 chips have to deal with lots of wrong guesses and mistakes which has to be discarded. This creates such a convoluted and complicated decoder stage that it is really hard to add more decoders. But for Apple, it is trivial in comparison to keep adding more.
In fact, adding more causes so many other problems that four decoders according to AMD itself is basically an upper limit for them.
This is what allows the M1 Firestorm cores to essentially process twice as many instructions as AMD and Intel CPUs at the same clock frequency.
One could argue as a counterpoint that CISC instructions turn into more micro-ops. For instance if every x86 instruction turned into 2 micro-ops while every ARM instruction turned into 1 micro-op, then four x86 decoders would produce the same number of micro-ops per clock cycle as an ARM CPU with 8 decoders.
Except this is not the case in the real world. Highly optimized x86 code rarely uses complex CISC instructions, which would translate into many micro-ops. In fact most will only translate into 1 micro-op.
However all these simple x86 instructions don’t help Intel or AMD. Because even if those 15 byte long instructions are rare, the decoders have to be made to handle them. This incurs complexity that blocks AMD and Intel from adding more decoders.
But AMDs Zen3 cores are still faster right?
As far as I remember from performance benchmarks, the newest AMD CPU cores, the ones called Zen3 are slightly faster than Firestorm cores. But here is the kicker: That only happens because the Zen3 cores are clocked at 5 GHz. Firestorm cores are clocked at 3.2 GHz. The Zen3 is just barely squeezing past Firestorm despite having almost 60% higher clock frequency.
So why doesn’t Apple increase the clock frequency too? Because higher clock frequency makes the chips run hotter. That is one of Apple’s key selling points. Their computers — unlike Intel and AMD offerings — barely need cooling.
In essence, one could say Firestorm cores really are superior to Zen3 cores. Zen3 only manages to stay in the game by drawing a lot more current and getting a lot hotter. Something Apple simply chooses not to do.
If Apple wants higher performance they are simply going to add more cores. That lets them keep watt usage down while offering more performance.
The future
It seems AMD and Intel have painted themselves into a corner on two fronts:
- They don’t have a business model that makes it easy to pursue heterogeneous computing and SoC designs.
- Their legacy x86 CISC instruction set is coming back to haunt them, making it hard to improve OoO performance.
Read more: Intel, ARM and the Innovators Dilemma
It doesn’t mean game over. They can increase the clock frequency and use more cooling, throw in more cores, beef up the CPU caches, etc. But they are both at a disadvantage. Intel is in the worst situation, as their cores are already soundly beaten by Firestorm, and they have weak GPUs to integrate with an SoC solution.
The problem with throwing in more cores is that for typical desktop workloads you reach diminishing returns with too many cores. Sure lots of cores are great for servers.
However here companies such as Amazon and Ampere are attacking with monster CPUs with 128 cores. This is like fighting the western and eastern front at the same time.
But fortunately for AMD and Intel, Apple doesn’t sell their chips on the market. So PC users will simply have to put up with whatever they are offering. PC users may jump ship, but that is a slow process. You don’t leave immediately a platform you are heavily invested in.
But young professionals, with money to burn without too deep investments in any platform, may increasingly turn to Apple in the future, beefing up their hold on the premium market and consequently their share of the total profit in the PC market.
Source : https://debugger.medium.com/why-is-apples-m1-chip-so-fast-3262b158cba2



No comments
Post a Comment